The Next ODS: Databricks Real-Time Mode, IBM's Confluent Acquisition, and What It Means for Financial Services
- Databricks Real-Time Mode (RTM) hit GA in March 2026 with single-digit millisecond p99 latency. For most ODS workloads, it eliminates the need for a separate Flink or Kafka Streams layer.
- IBM closed its $11B acquisition of Confluent on March 17, 2026. This gives IBM the dominant managed Kafka platform and fills the real-time data plumbing gap in its AI and hybrid cloud strategy.
- Together, these two moves create a cleaner ODS stack: Confluent/Kafka for event capture, Databricks RTM for processing and serving, Unity Catalog for governance. Fewer engines, less operational overhead.
- Already shipped: Zerobus Ingest and Lakebase both reached general availability in February 2026. Direct-to-lakehouse ingestion and Postgres-class OLTP now live inside the platform, which keeps compressing the ODS stack further.
Two things happened in the past six months that, separately, would each be worth paying attention to. Together, they could reshape how we build operational data stores for capital markets.
What actually changed
In August 2025, Databricks shipped Real-Time Mode (RTM) as a public preview inside Structured Streaming. It hit general availability in March 2026. The benchmarks are striking: latency dropping to sub-second, with many workloads hitting single-digit milliseconds. For context, micro-batch mode (which most production streaming jobs use today) runs at 10 to 30 second intervals. RTM closes that gap by an order of magnitude without requiring teams to rewrite their Spark code. You flip a configuration switch.
Two days before that, on March 17, IBM completed its acquisition of Confluent for roughly $11 billion. Confluent is the company behind managed Apache Kafka, and Kafka is the backbone of event streaming at most major banks. The deal had been announced the previous December, but seeing it close brings the implications into focus.
I spend my days designing ODS architectures for capital markets firms. These two events change the picture in ways that I think are worth laying out.
Why Databricks RTM matters for ODS
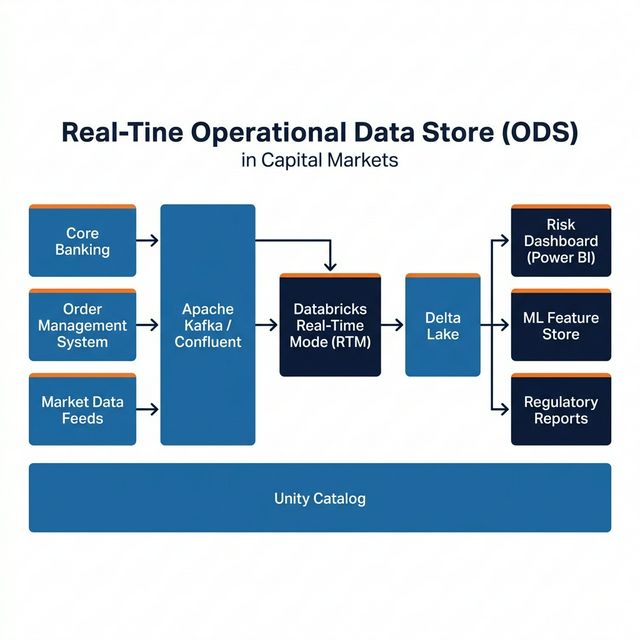
Until now, building a low-latency ODS on Databricks meant accepting a compromise. Structured Streaming is mature and well-governed, but micro-batch introduces an inherent floor on how fast data moves. For intraday risk, that floor was usually acceptable. For fraud detection or real-time pricing, it wasn't. Teams that needed sub-second latency had to bolt on Apache Flink or Kafka Streams as a separate processing layer, creating a dual-engine architecture that's expensive to run and painful to maintain.
RTM changes that tradeoff. If your Structured Streaming jobs can now process events continuously with sub-second latency, the argument for running a separate streaming engine gets much weaker. You keep one execution framework, one set of monitoring, one governance model through Unity Catalog. The operational simplification is significant.
I want to be specific about what this enables in an ODS context:
- Position updates in true real-time. A trade executes, the position view refreshes in milliseconds, not seconds. Risk desks see current state, not stale state.
- Streaming materialized views. Pre-computed aggregations (P&L by desk, exposure by counterparty) update continuously rather than on micro-batch intervals.
- Inline data quality gates. Validation logic runs inside the streaming pipeline at processing speed, catching data issues before they propagate downstream.
- Feature serving for ML models. Risk models that need fresh features (latest position, recent trade velocity) can pull from RTM-powered feature tables instead of stale batch snapshots.
A practical note
RTM is still new. I'd run it in parallel with micro-batch on non-critical workloads first. The latency numbers are impressive, but production financial workloads need weeks of stability data before you bet your risk desk on them.
Why IBM acquiring Confluent is strategic
Here's my read on this, and I want to be clear that this is personal analysis, not an IBM talking point.
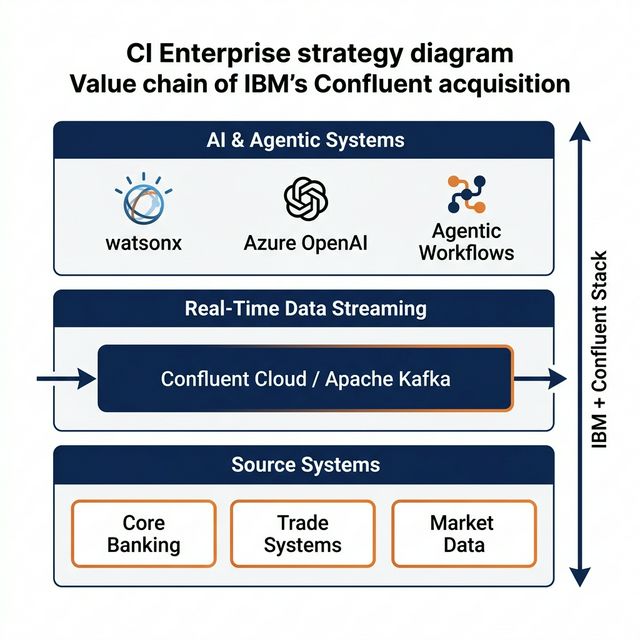
IBM has spent the past several years repositioning itself around AI and hybrid cloud. The watsonx platform, the Red Hat integration, the consulting push around generative AI. All of it points in the same direction: IBM wants to be the company that helps enterprises put AI into production, not just build demos.
But here's the gap that existed before this deal. AI models, whether they're generative copilots or agentic workflows, are only as useful as the data feeding them. And for financial services, that data needs to be real-time. A fraud detection agent running on stale data is just a reporting tool with extra steps. A KYC automation system that can't stream new watchlist updates is manually gated from the start.
Confluent fills that gap in a way that's hard to replicate organically. Here's what IBM gets:
- The streaming layer banks already run on. Kafka is not optional infrastructure at most Tier-1 financial institutions. It's the nervous system. Owning Confluent means IBM now controls a critical pipeline component that sits between source systems and every downstream consumer.
- A cloud-native, platform-agnostic streaming service. Confluent Cloud runs on AWS, Azure, and GCP. That fits IBM's hybrid cloud story. IBM can now offer a managed streaming layer regardless of which cloud a client is on.
- Direct integration with watsonx, confirmed on day one. This is no longer speculation. IBM named watsonx.data, IBM MQ, webMethods, and IBM Z as day-one integration targets, with Confluent streaming live operational events straight into watsonx.data under its lineage and policy controls. KYC document streams, trade event feeds, and market data ticks can now flow into agentic AI systems without a batch boundary. The IBM Z tie is the one I would not overlook: it puts real-time event capture at the mainframe transaction source, where most banking data still originates.
- A Flink play. Confluent has invested heavily in Apache Flink as a stream processing engine. IBM now has a strong Flink offering alongside its existing middleware stack. For clients who need complex event processing beyond what Structured Streaming handles, that's a meaningful option.
The $11 billion price tag is steep, but I think the strategic logic holds. IBM was missing the real-time data plumbing layer, and Confluent is the market leader. Building that capability in-house would have taken years and billions anyway, with no guarantee of adoption.
How these two moves intersect
This is where it gets interesting. Databricks RTM reduces the need for a separate streaming engine between Kafka and the lakehouse. At the same time, IBM (now the owner of Confluent/Kafka) is trying to position Confluent as the universal data streaming layer that feeds everything, including lakehouses.
Are they competing? Partially. But I think the more likely outcome is a layered architecture where both have a clear role:
- Confluent/Kafka stays as the event bus and integration layer. It captures events from source systems (core banking, OMS, market data feeds) and distributes them to multiple consumers. This is what Kafka does best, and no one is seriously trying to replace it here.
- Databricks RTM becomes the processing and analytics engine. It consumes from Kafka, applies transformations, updates materialized views, serves features to ML models, and writes governed Delta tables. The shift from micro-batch to continuous processing means the handoff from Kafka to lakehouse no longer introduces a latency penalty.
For an ODS architecture, this is actually a cleaner separation of concerns than what most firms run today. Kafka handles event capture and distribution. Databricks handles processing, storage, governance, and serving. You don't need Flink in the middle anymore for most use cases, which simplifies the stack considerably.
What this means for the ODS I build
I've been designing ODS platforms on Databricks and Fabric for capital markets firms. Here's how I'm thinking about updating those reference architectures:
- Adopt RTM for latency-sensitive layers. Position aggregation and risk views are the first candidates. Start with non-critical workloads in parallel, validate stability, then migrate the primary streams.
- Keep Kafka (now Confluent/IBM) as the event backbone. The ODS ingestion layer doesn't change. If anything, IBM's ownership of Confluent may accelerate enterprise Kafka adoption at firms that were hesitant about a smaller vendor.
- Account for Zerobus Ingest. Databricks made this generally available in February 2026 as a serverless, direct-to-lakehouse streaming path that does not need an intermediate message bus. It sustains sub-five-second latency at better than 10 GB/sec aggregate per table. It is positioned for simpler ingestion patterns (operational systems, telemetry) rather than the complex multi-consumer topologies Kafka excels at, so it does not replace Kafka in a serious capital markets ODS. It does mean the simpler ingestion edges of the architecture have a lighter option now.
- Factor in Lakebase. Databricks' serverless Postgres engine reached general availability in February 2026. It can handle the transactional layer of an ODS that traditionally needed a separate operational database. The convergence of real-time processing, governed analytics, and transactional storage on one platform is no longer a roadmap promise. It is a design option available today.
The bigger picture
Step back far enough and the pattern is clear. The streaming data market is consolidating rapidly. Databricks is building native real-time into the lakehouse. IBM just bought the largest managed Kafka provider. Microsoft Fabric has Eventstream. Snowflake has Dynamic Tables. Everyone is racing toward the same goal: eliminate the gap between when data is created and when it's usable.
For those of us building ODS platforms in financial services, this is mostly good news. More competition means better tooling, lower latency, and more options. But it also means the architecture decisions we make today will lock us into vendor relationships that are shifting underneath us.
A few months on from these moves, the early signal is in the product integrations, not the press releases. IBM named watsonx.data and IBM Z as day-one Confluent targets. Databricks shipped Zerobus and Lakebase to general availability. Real-Time Mode is GA. The roadmap is becoming product faster than most modernization cycles can absorb it.
My advice has not changed, and the last few months have only sharpened it. Design for portability where you can, because Delta Lake and open table formats are what keep you from being captured by any one vendor's real-time story. Pick the right tool for each layer instead of consolidating onto a single platform out of convenience. And sequence the migration so the risk desk feels the benefit first and the governance story holds up to an examiner. This is the work IBM Consulting does with capital markets clients now: not selling a product, but turning a fast-moving vendor landscape into an architecture that survives the next shift.
"The best ODS architectures aren't built around a single platform. They're built around clear layer boundaries, with each component doing the one thing it does best."
Want to talk ODS architecture?
I design streaming data platforms for capital markets. Happy to discuss how these shifts affect your roadmap.
Book a Session